Manuel utilisateur de l'environnement Vaniila / Notebooks
Sommaire
- Introduction
- Modalités d’accès aux environnements
- L’interface JupyterLab
- Accès simultanés - avertissement
- Caractéristiques de l’environnement d’exécution
- Mise à jour de l'environnement / ajout de nouveaux modules
- Répertoire 'work' et sauvegarde des données
- Données relatives aux use cases AI4industry
- Partage de fichiers avec les encadrants et membres des autres équipes du use case
- Accès à des ressources extérieures
- Trucs et astuces divers
- Introduction aux notebooks et aux outils de l'écosystème par l'exemple
- Troubleshooting
- Contacts / Assistance technique
Introduction
Le CATIE fournit, au travers de sa plateforme Vaniila, un service Cloud permettant :
- l’édition et l’exécution de notebooks Jupyter, documents électroniques pouvant rassembler, dans un même document, textes, images et code informatique exécutable
- et plus largement la création, la manipulation de fichiers et l’exécution de scripts, au travers d’environnements virtuels Linux basés sur la mise en œuvre de conteneurs Docker dédiés
Le service proposé prend appui sur JupyterLab, une application web couramment utilisée dans le domaine de la data science et permettant l’exploration de jeux de données, la mise au point d’algorithmes de machine learning et leur documentation. Ainsi donc que sur la technologie Docker, qui permet la création de machines virtuelles légères et cloisonnées fournissant un environnement de travail basé sur Linux.
Modalités d’accès aux environnements
L’accès aux conteneurs d’environnement s’effectue à l’aide d’un navigateur web (de préference Firefox ou Google Chrome), au travers de serveurs d’authentification qui permettent ensuite de se connecter aux conteneurs proprement dits.
Le premier serveur d’authentification, destiné aux encadrants et aux participants aux use cases :
- CATIE
- MAISON PARIES
est accessible à l’adresse : https://ai4i1-jenv.vaniila.ai.
Le second, destiné aux participants aux uses cases:
- CAP2020
- EINDEN
- EURLERTS
- KARIBOO
- LECTRA
- STM ELECTRONICS
- PRODITEC1
- SERLI
est accessible sur https://ai4i2-jenv.vaniila.ai.
Le troisième, destiné aux participants aux uses cases:
- CONNECTIV-IT
- ENEDIS
- PORT LA ROCHELLE
- PRODITEC2
- TCS
- UGOFRESH
- WYMMO
est accessible sur https://ai4i3-jenv.vaniila.ai.
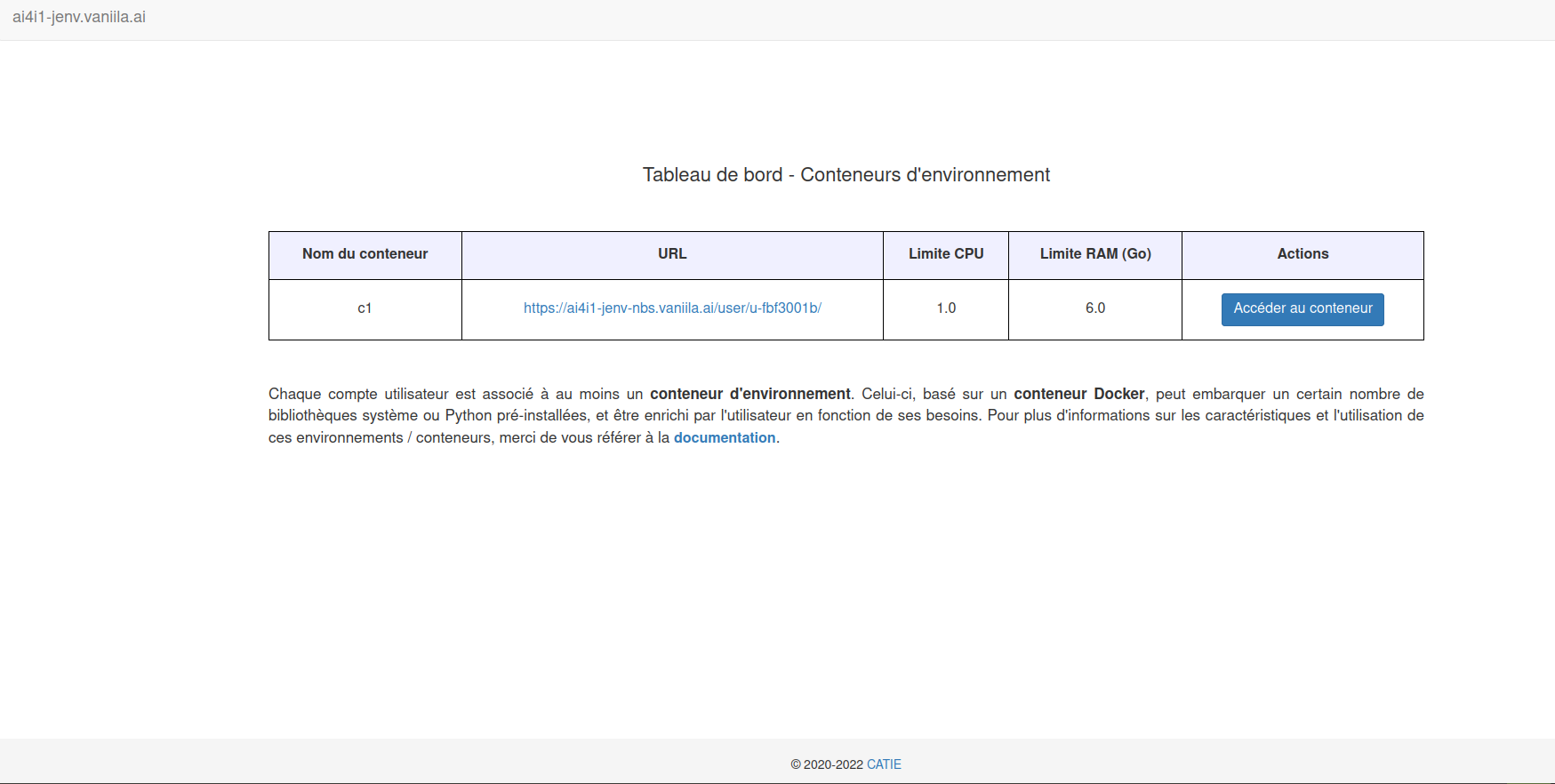
Aperçu du tableau de bord authentification / accès aux conteneurs
Chaque groupe de participants dispose d’un accès avec identifiant et mot de passe partagé entre tous les membres de ce groupe. Les identifiants associés aux différents groupes seront communiqués par les organisateurs.
Chaque groupe rattaché à un use case dispose de d'un conteneur d’environnement.
Les responsables de use cases et encadrants disposent également d’accès indépendants à des conteneurs leur permettant de tester et développer des algorithmes.
Pour toute question relative aux comptes et accès, merci de nous contacter à l'adresse : support@vaniila.ai.
L’interface JupyterLab
Chaque conteneur d’environnement est associé à une interface JupyterLab permettant la création et l’édition de notebooks, ainsi que des intéractions avec le système Linux sous-jacent au travers notamment d’un terminal en ligne de commande.
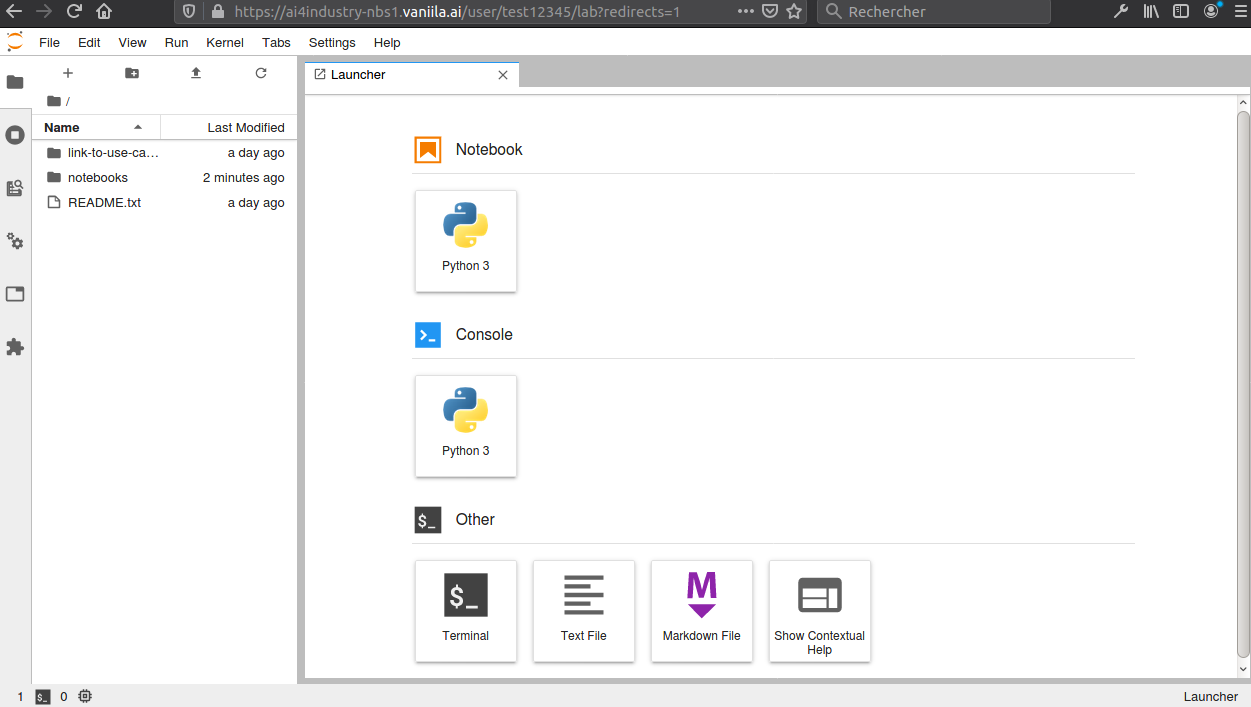
Aperçu général de l'interface JupyterlLab
Vue édition d'un notebook
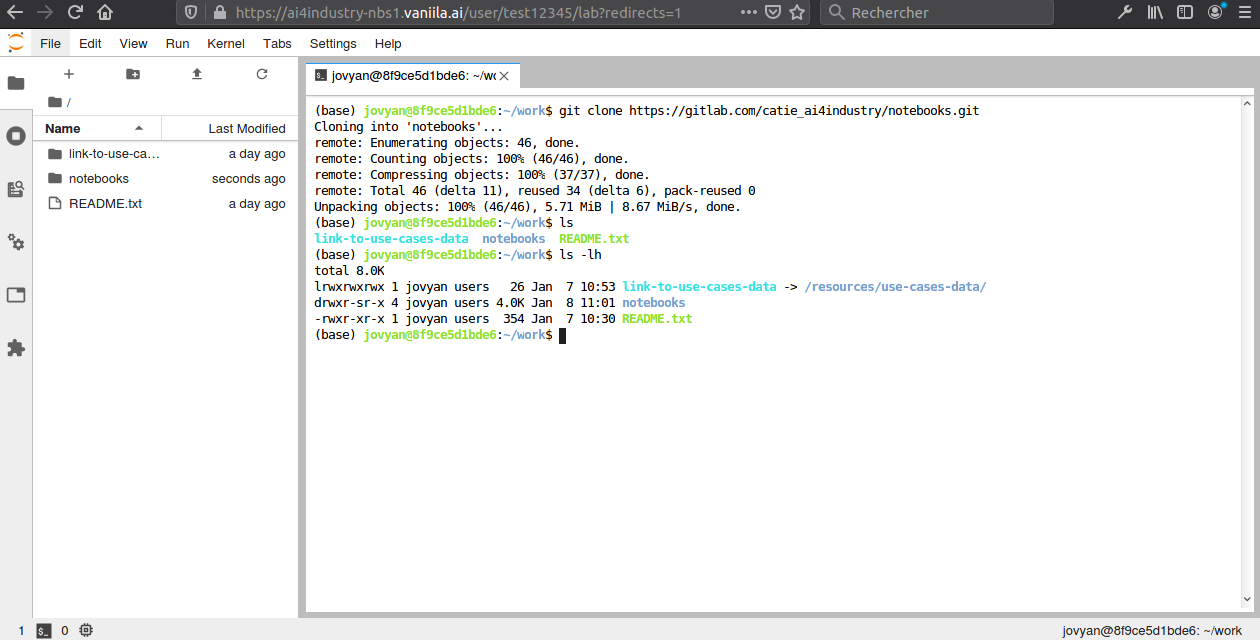
Vue session de terminal
L’interface proposée fournit des fonctionnalités et outils permettant, essentiellement, d’intéragir avec un interpréteur de code Python.
L’utilisateur peut tout à la fois éditer des notebooks et scripts, les exécuter et en récupérer / exploiter les résultats.
Comme cela a déjà été évoqué elle permet en outre de lancer des sessions de terminal rendant possible les intéractions avec le système Linux exécuté en arrière plan.
Nous n’entrerons pas ici dans les détails relatifs aux caractéristiques et aux fonctionnalités de cet IDE et nous vous invitons plutôt à consulter sa documentation ainsi que les nombreux tutoriels accessibles en ligne à son sujet.
Accès simultanés au compte - avertissement
Il est tout à fait possible de se connecter simultanément, à plusieurs, au même compte et à un même conteneur d’environnement, depuis des ordinateurs / navigateurs web différents.
Toutefois, dans ce cas, vous devrez bien prendre garde à ne pas éditer les mêmes notebooks au même moment, sous peine de perdre une partie ou la totalité du travail récemment effectué sur ceux-ci.
Caractéristiques de l’environnement d’exécution
Les conteneurs d’environnement JupyterLab mis à disposition ici sont basés sur Ubuntu 22.04 en mode serveur. La version de Python installé est la 3.10.
Les ressources allouées à chaque conteneur sont, par défaut, limitées de la façon suivante :
- 4 vCore max
- 12 Go de RAM max (tout programme lancé et consommant plus de 12 Go de RAM sera automatiquement interrompu par le système)
Ces ressources maximales peuvent, ponctuellement, être ajustées. En cas de besoin veuillez nous contacter à l'adresse : support@vaniila.ai.
Il est rappelé que les environnements proposés n’intègrent pas d’accès à des GPUs.
Les environnements fournis peuvent, selon le contexte d’accès (encadrant, participant...)
inclure, de base, plusieurs bibliothèques ou modules préinstallés tels que numpy, pandas, tensorflow...
Mise à jour de l'environnement / ajout de nouveaux modules
Chaque environnement peut être « tuné », en fonction des besoins, avec la possibilité de d’installer de nouveaux modules ou de désinstaller les modules fournis et de les réinstaller dans des versions plus anciennes si nécessaire.
Pour cela on utilise le gestionnaire de paquets pip pré-installé, en
effectuant par exemple dans une session de terminal :
pip install tensorflowpour installer la dernière version du package tensorflowpip install tensorflow==2.2.0pour installer une version antérieure de ce package
Il est également possible d'installer un module python directement depuis un notebook en effectuant :
!pip install tensorflow
Attention toutefois, dans ce cas, car le ou les nouveaux modules installés ne seront pas toujours immédiatement disponibles dans le notebook en question. Pour qu'ils le deviennent, il sera parfois nécessaire de redémarrer le kernel en se rendant pour cela dans le menu Kernel > Restart Kernel...
L'installation de certains packages spécifiques peut par ailleurs, dans certains cas, nécessiter l'installation de bibliothèques système supplémentaires.
Dans ce cas on effectuera, par exemple, dans une session de terminal :
sudo apt-get update
sudo apt-get install build-essential
En cas de problèmes d'installation ou de configuration merci de nous contacter à l'adresse : support@vaniila.ai.
Veuillez noter le fait que ces opérations n'affectent pas les environnements des membres des autres groupes, chaque environnement étant compartimenté à l'intérieur d'un conteneur Docker dédié.
Répertoire 'work' et sauvegarde des données
L'utilisateur standard Linux des conteneurs d'environnement est
l'utilisateur jovyan. Celui-ci dispose d'un répertoire personnel
~/(alias de /home/jovyan/) dans lequel a été créé un répertoire
work/ destiné à recueillir tous les fichiers de travail des
utilisateurs : notebooks, scripts et résultats en particulier.
Sachez que seule la persistance du contenu du répertoire ~/work/ est garantie
en cas de problème nécessitant, par exemple, la régénération de votre conteneur.
Toute fichier enregistré en dehors de ce répertoire ~/work/, par exemple
directement dans le répertoire ~/, sera donc perdu si un problème nécessite la
réinitialisation du ou des conteneurs associés au compte.
Nous vous encourageons naturellement à sauvegarder, en parallèle, votre code ou vos données à l'intérieur de dépôts GitHub / GitLab par exemple.
Données relatives aux use cases AI4industry
Le répertoire ~/work/uc-data/ est destiné à recueillir les données associées
au use case à traiter.
Ce répertoire est vide à la première connexion à l'environnement et il
est nécessaire d'y rapatrier les données, en les synchronisant avec la source
distante uc-data à l'intérieur de laquelle l'entreprise a publié ses données.
Pour ce faire il suffit d'exécuter le script :
/home/jovyan/work/get-sync-use-case-data.sh
Notes :
1/ la première exécution de commande nécessite la saisie d'un nom d'utilisateur et d'un mot de passe.
Si vous être membre d'une équipe participante, ceux-ci sont les mêmes que ceux que utilisés pour se connecter à l'instance Vaniila.
Si vous êtes encadrant(e), ceux-ci vous ont normalement été adressés par mail (merci de nous contacter à l'adresse ai4i-data@vaniila.ai si vous ne les avez pas encore reçus).
2/ L'opération précédente a pour effet de configurer le logiciel rclone, pré-installé
dans les conteneurs, avec le nom d'utilisateur et le mot de passe précédemment saisis.
Cette saisie n'est normalement demandée qu'à la première utilisation du script.
En cas d'erreur lors de cette étape, veuillez, le cas échéant, corriger / mettre à jour la configuration avec les bonnes valeurs en effectuant :
rclone config update ai4i-uc-data user <username>
rclone config update ai4i-uc-data pass <password>
3/ Les exécutions suivantes du script /~/work/get-sync-use-case-data.sh
synchroniseront le contenu du répertoire ~/work/uc-data/ avec la source de données
distante.
Veuillez donc ne pas y enregistrer vos propres fichiers de travail, ceux-ci seront automatiquement supprimés s'ils se trouvent à cet emplacement lors des nouvelles tentatives de synchronisation.
4/ Pour l'utilisation du copier-coller dans JupyterLab, voir la section consacrée aux trucs et astuces.
5/ Les données du use case peuvent être rapatriées dans le conteneur par d'autres moyens que celui décrit ici.
Pou plus d'informations à ce sujet, veuillez SVP vous référer à notre documentation relative au service de partage de fichiers.
En cas de difficultés, merci de nous contacter à l'adresse support@vaniila.ai.
Partage de fichiers avec les encadrants, le responsable entreprise et les membres des autres équipes du use case
Participants et encadrants ont la possibilité d'échanger des fichiers au travers d'un répertoire partagé /shared, accessible en lecture / écriture par tous, au travers des protocoles SFTP et FTPS, via les outils sftp et lftp.
Ce répertoire partagé est par ailleurs accessible depuis des stations de travail avec interface graphique, au travers de clients web (http://ai4i-data.vaniila.ai) ou du logiciel Filezilla.
Pour plus d'informations à ce sujet, merci là encore de vous référer à notre documentation relative au service de partage de fichiers.
Le répertoire /shared est accessible par tous en écriture, prenez donc garde à ne pas y supprimer
accidentellement les données déposées par les autres intervenants !
Accès à des ressources extérieures
L'environnement proposé permet d'exécuter, en ligne de commande via un terminal,
des utilitaires tels que wget et git.
L'interface graphique de JupyterLab permet également d'uploader des fichiers dans le conteneur via le bouton prévu à cet effet "Upload files".
Il est également possible, depuis celle-ci, de rapatrier (download) des fichier
stockés dans votre instance. Pour cela on n'hésitera pas, si un grand nombre
de fichiers devaient être rapatriés, à générer des archives à l'aide des
utilitaires tar ou zip en ligne de commande (ne pas oublier d'ajuster les
options de sortie pour que l'archive soit bien générée dans un répertoire sur
lequel vous possédez des droits en écriture).
Trucs et astuces divers
Nous vous rappelons que la documentation de JupyterLab est disponible ici :
https://jupyterlab.readthedocs.io
Références utiles relatives à l'utilisation de Jupyter, à ses magic commands, etc.
Voici par ailleurs les raccourcis clavier permettant de copier / coller du contenu dans un terminal :
- copier :
Cmd+Csous Mac,Ctrl+Insertsous Windows ou Linux - coller :
Cmd+Vsous Mac,shift+Insertsous Windows ou Linux ou, selon le contexte,clic sur le bouton central de la souris
Introduction aux notebooks et aux outils de l'écosystème par l'exemple
Une introduction à l'utilisation des notebooks Jupyter et aux outils associés de l'écosystème Python (la bibliothèque pandas, en particulier) a été réalisée par Thomas GEFFROY, du CATIE, le lundi 16 janvier.
Nous vous proposons de télécharger ici le notebook support utilisé dans cette présentation.
N'oubliez pas d'installer les requirements associés (pip install req.txt) pour pouvoir le lancer correctement !
Troubleshooting
1/ Je ne vois pas de répertoire ~/work/data/ et/ou je ne trouve pas les utilitaires sftp / lftp / rclone
Il se peut que le répertoire vide /home/jovyan/work/uc-data/ n'existe pas à votre première connexion et que les
utilitare sftp / lftp / rclone ne soit pas pré-installé.
Dans ce cas veuillez effectuer :
mkdir /home/jovyan/work/uc-data/
sudo apt-get update
sudo apt-get install lftp sftp rclone
2/ Erreur : impossible de créer un nouveau notebook (erreur : "Unexpected error while saving file...")
Assurez-vous, lorsque vous tentez de créer un nouveau fichier en cliquant par
exemple sur le bouton "Nouveau Notebook Python 3", que vous vous êtes bien
positionné(e) à l'intérieur d'un répertoire sur lesquels vous possédez des
droits en écriture. Cette erreur se produit typiquement lorsque
vous êtes positionné(e) en dehors du répertoire ~/work/. Veuillez alors
vous repositionner dans ~/work/ en cliquant sur le bouton  situé en haut à gauche dans le volet d'exploration JupyterLab.
situé en haut à gauche dans le volet d'exploration JupyterLab.
3/ Erreur : impossible d'uploader un fichier dans mon conteneur (erreur : "Upload Error : Unexpected error while saving file...")
Même origine que l'erreur décrite précédemment : assurez vous que vous êtes positionné(e) dans un un répertoire sur lesquels vous possédez des droits en écriture.
4/ Je viens d'installer, à partir d'un notebook, un nouveau module python (via !pip install) mais il m'est impossible de l'importer (ModuleNotFoundError)
Rendez-vous dans le menu Kernel puis cliquez sur Restart Kernel.... Le module en question devrait pouvoir ensuite être importé depuis vos notebooks.
5/ Je viens d'installer un nouveau module python mais une erreur s'affiche au moment où je tente de l'importer
Il se peut que le module en question prenne appui sur une bibliothèque système
ne figurant pas parmi celles déjà installée dans votre conteneur. Dans ce cas
veuillez identifier la ou les bibliothèques manquantes puis les installer via
sudo apt-get update et sudo apt-get install comme indiqué plus haut. En cas
de problème persistant merci de nous contacter à l'adresse : support@vaniila.ai
en nous communiquant le message d'erreur retourné par l'interpréteur Python,
de manière à ce que nous installions les composants manquants ou ajustions la
configuration.
6/ Je suis encadrant et tente d'accéder au conteneur d'un groupe d'apprenants mais je n'y parviens pas bien que je dispose de ses identifiants de connexion
Pour switcher d'un compte à un autre vous devez :
1/ Tout d'abord vous déconnecter de votre instance JupyterLab en cliquant sur File / Logout
ou bien en activant directement l'URL https://ai4i1-nbs.vaniila.ai/hub/logout / https://ai4i2-nbs.vaniila.ai/hub/logout / https://ai4i3-nbs.vaniila.ai/hub/logout selon le serveur auquel vous avez été affecté(e).
2/ Vous déconnecter du serveur d'authentification via le menu "Déconnexion"
3/ Vous rendre sur https://ai4i1-jenv.vaniila.ai / https://ai4i2-jenv.vaniila.ai / https://ai4i3-jenv.vaniila.ai (en fonction du serveur affecté) et saisir les identifiants du nouveau compte auquel vous souhaitez vous connecter.
7/ Affichage intempestif d'un popup Your server at /user/..../ is not running. Would you like to restart it?
Problème temporaire apparaissant lorsque de gros volumes de données sont téléchargés simultanément par plusieurs groupes, ce qui réduit la bande passante disponible au niveau du serveur et entrave la communication entre les instances JupyterLab et celui-ci. Veuillez dans ce cas simplement cliquer sur "Dismiss".
8/ J'ai une erreur ImportError: libgthread-2.0.so.0: cannot open shared object file: No such file or directory lorsque j'essaie d'importer le module opencv cv2
Le module python cv2 n'est fonctionnel que si la bibliothèque système libglib2.0-0 a été préalablement installée.
Veuillez donc exécuter la séquence suivante :
sudo apt-get update
sudo apt-get install -y libglib2.0-0
pip install opencv-python
Puis vous assurer que tout est bon en effectuant :
python
>> import cv2
Contacts / Assistance technique
En cas de problèmes lié à l'utilisation de la plateforme merci de nous contacter :
- via le canal de visionconférence mis en place dans Teams, salle "Aide / Assistance technique > Assistance technique Vaniilia"
- et / ou par mail à l'adresse : support@vaniila.ai